Mastering Word Embeddings for NLP: A Comprehensive Guide
Written on
Chapter 1: Introduction to Word Embeddings
In the rapidly evolving field of Natural Language Processing (NLP), word embeddings have emerged as a crucial concept. As you delve deeper into this domain, you'll uncover valuable insights about data that can lead to innovative solutions for existing problems. We've previously discussed feature engineering techniques, such as TF-IDF and PMI, in earlier articles. You can find the links below for further reading. Now, let's progress to the next steps in feature engineering.
Feature Engineering: A Step Toward Data Analysis
Feature engineering in NLP is akin to vector compression, aimed at generating less sparse vectors for enhanced performance. Other dimensionality reduction techniques, such as Singular Value Decomposition (SVD), can also be utilized. Let's now explore the concept of word embeddings, including Word2Vec, CBOW, and SkipGram.

Understanding Word Embeddings
Word embeddings represent words in a dense vector format, bridging the gap between human comprehension and machine interpretation. Essentially, this process transforms text into an n-dimensional space, which is a pivotal step in addressing NLP challenges.
In contrast to one-hot encoding—where text is represented in a sparse vector format—word embeddings provide a denser representation.

By applying word embeddings to one-hot encoded vectors, we achieve a more compact and informative output.
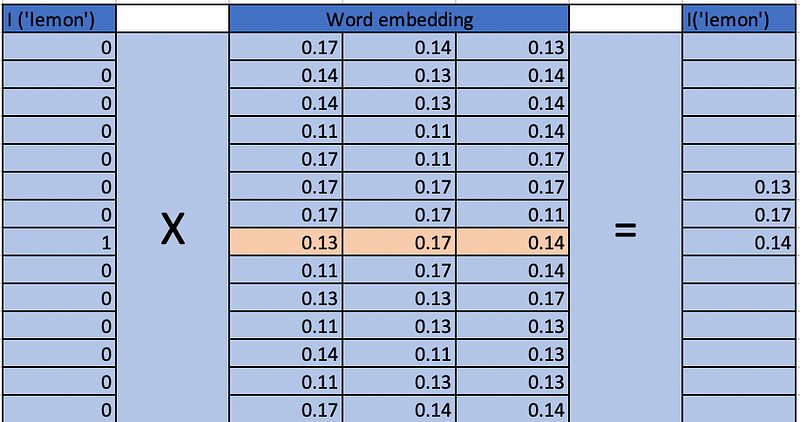
The final result is a matrix that is the product of one-hot encoding and word embeddings. This compact representation is ideal for feeding into neural networks, yielding improved performance.
Generating Word Embeddings
Word embeddings can be created using various techniques, including neural networks, co-occurrence matrices, and probabilistic models. A popular method for generating these embeddings is Word2Vec.
To convert words or text into vectors, you typically follow these steps:
- Define the task you want to predict.
- Process each sentence to create inputs and outputs for the task.
- Iterate through these inputs and outputs, applying the embeddings and models to generate predictions.
- Measure the discrepancy between predicted and expected outputs, adjusting the embedding weights through backpropagation.
- Repeat the process until satisfactory results are achieved.
Word2Vec comprises two architectures: Continuous Bag of Words (CBOW) and SkipGram, both designed to generate embeddings and identify synonymous words within a given context.
Challenges and Limitations
While powerful, word embeddings have certain limitations:
- They struggle to adapt to new words and may not generalize well to out-of-vocabulary (OOV) terms.
- There are no shared representations at sub-word levels.
- New tasks necessitate the creation of new embedding matrices for optimal results.
- They may not initialize advanced architectures effectively.
- They face difficulties in managing polysemy and homonymy.
Chapter 2: CBOW vs. SkipGram
#### CBOW (Continuous Bag of Words)
CBOW predicts a target word based on a set of context words. This is similar to the predictive text features you encounter in emails and messaging apps.
The model consists of:
- An input layer for context words.
- An output layer for the predicted word.
- A hidden layer that represents the number of dimensions for the current word.
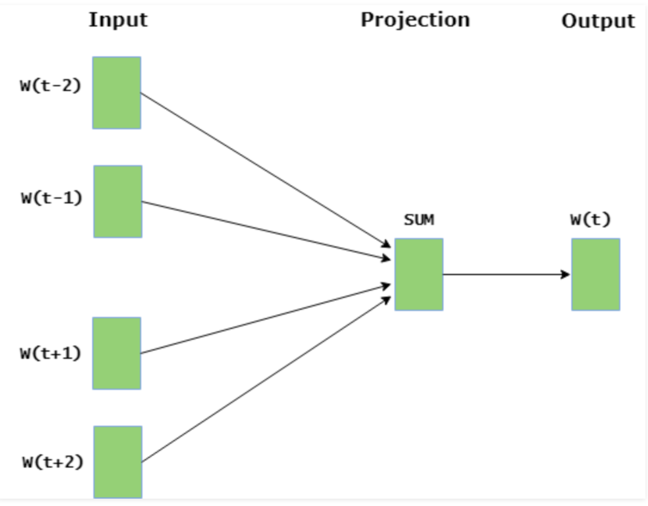
Simply put, you provide context words to the model, and it predicts the target word. In more complex scenarios, it can fill in blanks using prior and subsequent context.
#### SkipGram
SkipGram operates in a manner opposite to CBOW, predicting context words based on a given input word.
The model structure includes:
- An input layer for the current word.
- A hidden layer for dimensional representation.
- An output layer for context words.
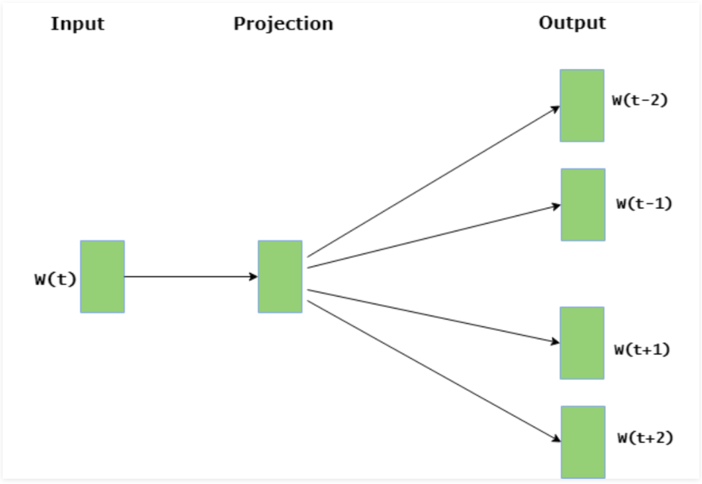
As illustrated, the model takes the current word as input and generates multiple context words surrounding it.
Conclusion: A Path Forward in NLP
This overview provides foundational knowledge on converting words to vectors, focusing on the essential methodologies of CBOW and SkipGram. Understanding these concepts will enhance your ability to address various NLP challenges effectively.
You may also consider leveraging pre-trained word embeddings, which offer both advantages and limitations. While they can simplify interpretation, their complexity can pose challenges.
As you explore further, you'll encounter additional topics like forward and backward propagation, loss functions, and model training. NLP is a dynamic field, and mastering its basics will empower you to navigate its vast landscape with confidence.
Happy Learning and Coding!
The first video introduces Word Embedding in Natural Language Processing, providing foundational knowledge crucial for deep learning applications.
The second video delves into Word2Vec, CBOW, and SkipGram, offering an in-depth understanding of these pivotal concepts in NLP.