Mastering Scikit-Learn Pipelines for Efficient Machine Learning
Written on
Introduction to Scikit-Learn Pipelines
When embarking on a Machine Learning (ML) project, several critical steps are typically followed, including:
- Handling Missing Values
- Encoding Categorical Features
- Applying Additional Transformations
- Training the Model(s)
A common mistake among beginners is to tackle these steps individually, which can lead to issues like data leakage. Fortunately, Scikit-Learn pipelines provide a more cohesive approach by consolidating these steps into a single, streamlined process. This article will delve into the significance of pipelines and guide you on how to implement them in your upcoming projects.
Table of Contents
- The Importance of Pipelines
- Components of a Pipeline
- Implementing Scikit-Learn Pipelines
- Tuning Hyperparameters in the Pipeline
- Bonus Content
- References
The Importance of Pipelines
Pipelines significantly simplify your code. Instead of executing each step separately, you can apply the entire pipeline to your dataset in one go, reducing code complexity and enhancing clarity.
Moreover, pipelines ensure that the same preprocessing steps applied to your training data are consistently applied to your test data. This uniformity reduces the risk of applying preprocessing steps incorrectly to the test set.
Additionally, pipelines allow for cross-validation of the preprocessing workflow—not just the model itself. This capability enables you to optimize preprocessing steps alongside your model.
Finally, employing a pipeline helps mitigate the risk of data leakage. Data leakage occurs when your ML model inadvertently accesses test data, and pipelines help ensure that processes are applied to the correct data subsets.
With these benefits in mind, let’s explore the building blocks of a valid pipeline.
Components of a Pipeline
When constructing your pipeline, it typically consists of several steps. According to the Scikit-Learn documentation, the first (n-1) steps should be transformer objects, while the final step can be either a transformer or an estimator.

Since pipeline objects execute steps sequentially, the order of operations is crucial. The following illustration highlights valid and invalid pipeline configurations.
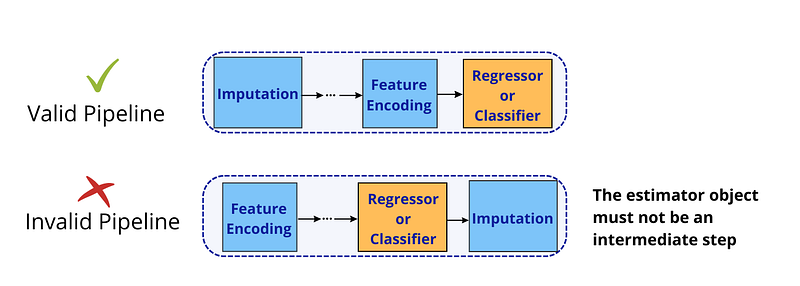
Now that we have covered the theoretical aspects, let’s move on to practical implementation.
Implementing Scikit-Learn Pipelines
We will utilize a subset of the well-known Titanic dataset and explore two scenarios based on the data types of the features. This example is inspired by a video tutorial from Data School.
In this case, we will employ the k-nearest neighbors classifier as our estimator.
Case 1: Features of the Same Data Type
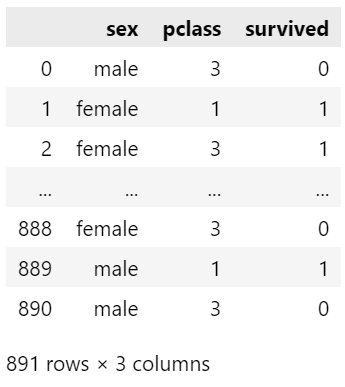
In this instance, the features are 'sex' and 'pclass', with the target variable being 'survived'. Given that both features are categorical, we will use one-hot encoding. We’ll assume that the feature set is represented by variable X and the target variable by y.
Step 1 — Import the required packages and modules.
Step 2 — Define the classification pipeline steps, structured as a list of tuples:
[(step1_name, scikit-learn object), ... , (stepN_name, scikit-learn object)]
Step 3 — Create an instance of the pipeline.
Step 4 — Conduct cross-validation on your pipeline.
Output (accuracy measure):
0.7867993220764548
Case 2: Features of Different Data Types
Here, we introduce an additional column, 'age', which is numeric.
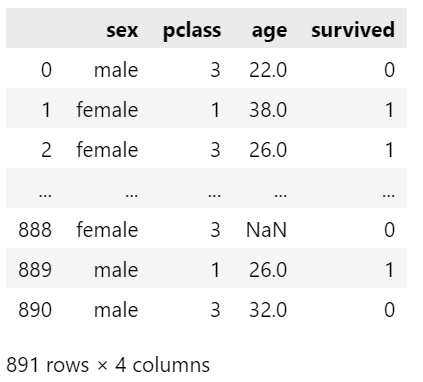
Step 1 — Import the necessary packages and modules.
Step 2 — Create distinct preprocessing pipelines for numeric and categorical features using ColumnTransformer().
Step 3 — Develop a classification pipeline and perform cross-validation.
Output (accuracy measure):
0.8014123407193523
Tuning Hyperparameters in the Pipeline
One of the primary advantages of utilizing pipelines is the ability to optimize the entire training workflow, not just the learning algorithm. Let’s explore how to integrate grid search cross-validation within the pipeline.
We will attempt to address two key questions:
- Should we opt for one-hot encoding or ordinal encoding?
- What is the optimal value of k for the k-nearest neighbors algorithm?
Using the same subset of the dataset from Case 2, we can proceed as follows:
Step 1 — Create a pipeline as demonstrated in Case 2.
Step 2 — Employ GridSearchCV on the pipeline. Here, we will specify a range of hyperparameters and execute a grid search on this parameter space. To reference a specific parameter in a pipeline step, use the syntax: step_name__parameter_name. For instance, for KNeighboursClassifier() named as KNN in our pipeline, its hyperparameter is n_neighbors. Thus, we would write KNN__n_neighbors to refer to this parameter.
Additionally, sub-pipelines can be addressed similarly, allowing for detailed tuning of hyperparameters.
From the results, we determine that the optimal configuration involves 11 neighbors with OneHotEncoder() as the categorical encoder.
Bonus Content
Some transformations, such as log transformation, may not be readily available in Scikit-Learn. However, using FunctionTransformer(), you can convert any custom function into a Scikit-Learn transformer. Feel free to check out the accompanying notebook that illustrates function transformers and includes all the code featured in this article.
References
- Scikit-learn developers, 10. Common pitfalls and recommended practices (2022), scikit-learn.org (accessed July 19, 2022)
- Data School, How do I encode categorical features using scikit-learn? (2019), youtube.com (accessed July 19, 2022)
- Scikit-learn developers, sklearn.pipeline.Pipeline (2022), scikit-learn.org (accessed July 19, 2022)
- Scikit-learn developer, 6.1. Pipelines and composite estimators (2022), scikit-learn.org (accessed July 19, 2022)
Before You Go!
I hope you found this guide insightful and beneficial. If you're interested in more content like this, consider following me on Medium. Also, feel free to buy me a coffee to support my work.