The Future of Data Storage: Data Lakes, Warehouses, and Lakehouses
Written on
Understanding Data Lakes and Data Warehouses
In the realm of Big Data storage, the terms "Data Lake" and "Data Warehouse" are frequently encountered, yet they denote different concepts. A Data Lake serves as a vast reservoir for unprocessed raw data that has no predetermined purpose. Conversely, a Data Warehouse is a structured repository that holds filtered and processed data designed for specific analytical tasks.
As depicted in the following video, the approaches utilized by these two systems vary significantly:
Data Lakes predominantly employ the ELT (Extract, Load, Transform) method, which allows for a schema to be applied at the time of reading data. In contrast, Data Warehouses typically rely on the traditional ETL (Extract, Transform, Load) process, managing structured data within relational databases.
The Necessity of Both Solutions
Despite the rising popularity of Data Lakes, it is crucial to recognize that both Data Lakes and Data Warehouses have essential roles to play. Each solution caters to distinct use cases, and the advent of Data Lakehouses, alongside hybrid Data Warehouse models incorporating NoSQL functionalities, represents a promising development in data management strategies.
The Emergence of Data Lakehouses
Data Lakehouses blend the advantages of both Data Lakes and Data Warehouses, facilitating unified governance and seamless data movement. My personal experience suggests that establishing a Data Lake can be accomplished more swiftly. Once the data is collected, a Data Warehouse can be constructed atop it, creating a hybrid solution.
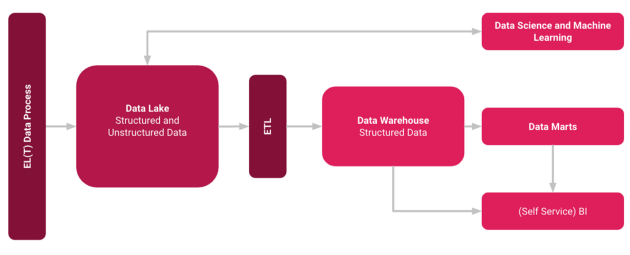
This shift signals the decline of the rigidly structured Data Warehouse. By accelerating the deployment of dashboards and analyses, organizations can foster a more data-driven culture. Leveraging modern SaaS solutions and utilizing ELT methodologies instead of ETL can further streamline development processes. For instance, Google’s Data Lakehouse employs Cloud Storage for its Data Lake and BigQuery for its Data Warehouse, showcasing a hybrid model where BigQuery also exhibits features of a Data Lake.
Building a Data Lakehouse
To delve deeper into the practicalities of constructing a Data Lakehouse, we can examine the technologies and services involved. The architecture illustrated below, implemented within the Google Cloud ecosystem, utilizes Cloud Storage and BigQuery for data storage. The robust connectivity in Google Cloud enables effortless data exchange between services, facilitating analysis, machine learning, and various other applications.
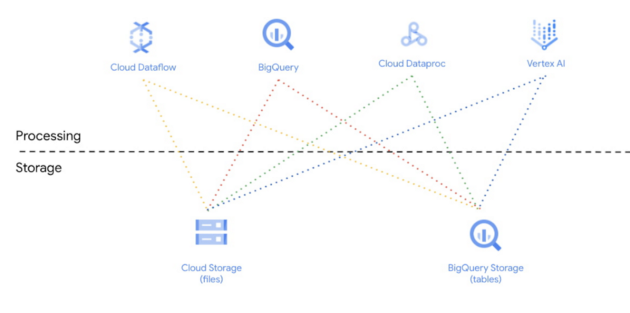
Similar architectures can also be established using alternative providers such as AWS or Microsoft Azure, which offers Azure Synapse Analytics as a comprehensive analytical platform. Azure has already adopted several Data Lakehouse strategies, including the capability to integrate data from a Data Lake as a virtual table.
Conclusion
Rather than viewing Data Lakes as a replacement for Data Warehouses, it is more accurate to see them as complementary solutions in the data integration landscape. By importing raw data into a Data Lake, organizations can accommodate diverse data types. Subsequently, this data can be processed through the traditional ETL pipeline into a Data Warehouse, leading to the creation of a Data Lakehouse or hybrid setup.
Sources and Further Reading
[1] Talend, Data Lake vs. Data Warehouse
[2] IBM, Charting the data lake: Using the data models with schema-on-read and schema-on-write (2017)
[3] AWS, What is a Lake House approach? (2021)