Innovative PaLI Model: Bridging Language and Images in 100 Tongues
Written on
Chapter 1: The Evolution of Neural Networks
In recent years, there has been a significant push to enhance the capabilities of neural networks. This has manifested in two key areas: the development of more complex models boasting an increasing number of parameters and a substantial rise in the volume of training data utilized. This trend has been evident in both textual and visual tasks.
When it comes to textual models, the expansion in capacity has led to improved performance and intriguing emergent behaviors, as seen with models like GPT, GLaM, PaLM, and T5. On the visual side, convolutional neural networks dominated the field until vision transformers emerged as the preferred architecture.
These advancements across both textual and visual domains have paved the way for the creation of vision-language models, a new frontier that integrates both image and text inputs for a myriad of applications.
The first video discusses the PaLI model's capabilities in processing language-image tasks across 100 different languages.
Section 1.1: What Are Vision-Language Models?
Vision-language models serve to analyze both images and text, enabling them to perform diverse tasks. This year, we witnessed remarkable achievements from models like DALL-E and Stable Diffusion, which can generate intricate images from textual prompts. However, these are merely a fraction of what vision-language models can accomplish:
- Visual Captioning (VC): This task involves creating textual descriptions for visual inputs such as images or videos.
- Visual Question Answering (VQA): Here, the model answers questions based on visual content.
- Visual Commonsense Reasoning (VCR): This entails inferring common knowledge from visual inputs.
- Visual Generation (VG): This function generates visual outputs based on textual prompts.
- Optical Character Recognition (OCR): This process converts images containing text into readable text formats for computers.
Despite many models being primarily trained on English data, it's crucial to include other languages, given the estimated 7,000 languages worldwide. This week marked the introduction of PaLI, a language-visual model capable of executing tasks in 100 languages.
Section 1.2: Architectural Insights
The PaLI model comprises a total of 17 billion parameters, with 13 billion dedicated to language processing and 4 billion for visual components. Its architecture features a transformer encoder for text and an autoregressive transformer decoder for generating text outputs. The visual input is processed using a vision transformer (ViT) linked to the encoder.
A critical aspect of the PaLI model is its reuse of components from previously trained uni-modal vision and language models, such as mT5-XXL and large ViTs. This approach not only facilitates the transfer of learned capabilities but also reduces computational costs.
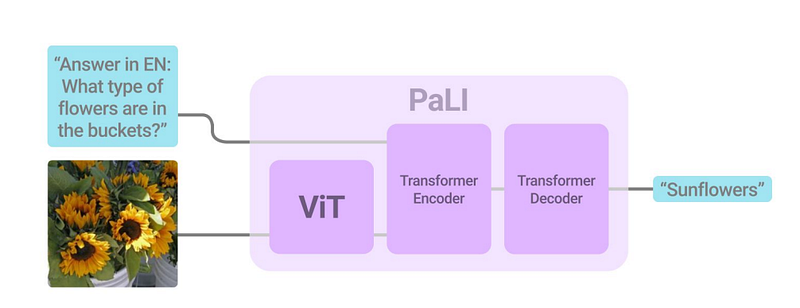
The model's architecture showcases a blend of components to enhance its performance.
Chapter 2: Dataset Construction and Training Strategies
The authors developed a dedicated dataset for the PaLI model, named WebLI. This dataset was constructed by gathering images and text from the web, encompassing data from 109 languages rather than limiting it to English. In total, they amassed 12 billion images along with corresponding alt-texts and extracted text from these images using the GCP Vision API, resulting in 29 billion image-OCR pairs. Ultimately, one billion images were selected for training.
The second video provides insights into the PaLI-X model, highlighting its advancements in vision-language tasks.
Section 2.1: Training Methodology
The training strategy was designed to optimize the model's ability to process inputs (image + text) and produce text outputs. The training incorporated a variety of pre-training tasks, such as text corruption and captioning, while maintaining the fundamental structure of input-output relationships. This approach enables the model to generalize effectively and tackle a range of tasks.

Examples of inputs and outputs used during the training phase.
Conclusions
The PaLI model represents a significant advancement in the field of vision-language processing, achieving state-of-the-art results across numerous challenging tasks not only in English but also in multiple languages. While it has made impressive strides, the development of visual language models is likely to continue, paving the way for even more innovative solutions that address biases and promote inclusivity in AI.
For those interested in exploring further, feel free to connect with me on LinkedIn or check out my GitHub repository for resources related to machine learning and AI.